在 nixos 配置中添加:
# Setup Clash
programs.clash-verge = {
enable = true;
serviceMode = true;
tunMode = true;
};开启了 tunMode 和 serviceMode
Stuff I learned recently.
在 nixos 配置中添加:
# Setup Clash
programs.clash-verge = {
enable = true;
serviceMode = true;
tunMode = true;
};开启了 tunMode 和 serviceMode
当我在 cronjob 中设置:LOGSEQ_FOLDER=$HOME/logseq 时 (这个语法会被 cronjob 设置为环境变量),在后续的命令调用 LOGSEQ_FOLDER 这个变量的时候,并不能正确的获取到 $HOME 变量。但是我们可以尝试在 SHELL 中运行命令export LOGSEQ_FOLDER=$HOME/logseq,然后从环境变量中查找 env|grep LOGSEQ_FOLDER 得到结果是:/home/alex/logseq, 为什么?
因为 cronjob 中不会对环境变量的值 $HOME 二次展开,但是 shell 中,是直接展开了的!
LOGSEQ_FOLDER=$HOME/logseq 表示的是一个键值对,原样放入子进程的模块的环境变量中。LOGSEQ_FOLDER=$HOME/logseq 表示的是一个表达式,会先计算,再展开,所以你 export 后的环境变量就已经是展开过后的了。在 windows 下的手机连接有时候会报错:“Microsoft 手机连接 - 无法连接到你的 Android 设备,因为你正在尝试访问中国以外的应用程序,目前我们不支持漫游区域。”
只需要添加对应的 “dcg.microsoft.com” 为直连即可。
以 Bitwarden 为例:
ls -la /Applications/ | grep -i bitwardenspctl -a -t exec -vvv /Applications/Bitwarden.app输出如下:
/Applications/Bitwarden.app: accepted
source=Notarized Developer ID
origin=Developer ID Application: 8bit Solutions LLC (LTZ2PFU5D6)如果 source 是 Mac App Store, 那就是通过 app store 下载的,反之如果 source 是 Notarized Developer ID, 那就是通过 DMG 下载的。
这个命令是 macOS 系统中用于 Gatekeeper(门禁)安全机制的 spctl 工具的一个用法。具体解释如下:
spctl -a -t exec -vvv /Applications/Bitwarden.appspctl
是 macOS 自带的命令行工具,全称是 System Policy Control,用于管理系统策略,尤其是 Gatekeeper 对应用程序的验证和授权。
-a(或 --assess)
表示“评估”(assess)指定的项目,即检查该应用是否被系统策略允许运行。
-t exec(或 --type execute)
指定评估类型为“可执行”(executable),即检查该应用是否可以被当作可执行程序运行。这是针对应用程序(.app)的标准类型。
-vvv
表示输出详细(verbose)信息,v 越多,输出越详细。-vvv 是非常详细的输出,会显示签名信息、证书链、权限来源等。
/Applications/Bitwarden.app
要评估的目标应用程序路径,这里是安装在应用程序文件夹中的 Bitwarden 密码管理器。
检查 Bitwarden.app 是否通过了 macOS 的 Gatekeeper 验证,是否被允许运行。
运行后,你会看到类似这样的输出(取决于实际情况):
/Applications/Bitwarden.app: accepted
source=Apple Notarized Developer ID
origin=Developer ID Application: Bitwarden Inc. (XXXXX)在 /etc/nixos/configuration 中这样配置即可:
services.interception-tools =
let
itools = pkgs.interception-tools;
itools-caps = pkgs.interception-tools-plugins.caps2esc;
in
{
enable = true;
plugins = [ itools-caps ];
# requires explicit paths: https://github.com/NixOS/nixpkgs/issues/126681
udevmonConfig = pkgs.lib.mkDefault ''
- JOB: "${itools}/bin/intercept -g $DEVNODE | ${itools-caps}/bin/caps2esc -m 1 | ${itools}/bin/uinput -d $DEVNODE"
DEVICE:
EVENTS:
EV_KEY: [KEY_CAPSLOCK, KEY_ESC]
'';
};参考连接:https://discourse.nixos.org/t/best-way-to-remap-caps-lock-to-esc-with-wayland/39707/6
logseq 中 api 返回的 uuid 在真实的 block 中未必会有,需要检查是否有 id 这个属性才能够正确获取到:
def ensure_uuid_property(
self, blocks: List[Dict[str, Any]]
) -> List[Dict[str, Any]]:
updated_blocks = []
for block in blocks:
if "properties" not in block or "id" not in block["properties"]:
# Logseq block UUID is typically in block['uuid']
block_uuid = block.get("uuid")
if block_uuid:
print(f"Ensuring uuid property for block: {block_uuid}")
self.upsert_block_property(block_uuid, "id", block_uuid)
# Update the block in memory for consistency
if "properties" not in block:
block["properties"] = {}
block["properties"]["id"] = block_uuid
updated_blocks.append(block)
return updated_blocks
使用本地 embddings 遇到如下问题:
qwen3_embdings = OpenAIEmbeddings(
model="text-embedding-qwen3-embedding-0.6b",
base_url="http://127.0.0.1:1234/v1",
)运行时报错:
Traceback (most recent call last):
File "/Users/zhaochunqi/ghq/github.com/zhaochunqi/ai-agents-learning/main.py", line 20, in <module>
_ = vector_store.add_documents(documents=all_splits)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/zhaochunqi/ghq/github.com/zhaochunqi/ai-agents-learning/.venv/lib/python3.12/site-packages/langchain_core/vectorstores/in_memory.py", line 195, in add_documents
vectors = self.embedding.embed_documents(texts)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/zhaochunqi/ghq/github.com/zhaochunqi/ai-agents-learning/.venv/lib/python3.12/site-packages/langchain_openai/embeddings/base.py", line 590, in embed_documents
return self._get_len_safe_embeddings(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/zhaochunqi/ghq/github.com/zhaochunqi/ai-agents-learning/.venv/lib/python3.12/site-packages/langchain_openai/embeddings/base.py", line 480, in _get_len_safe_embeddings
response = self.client.create(
^^^^^^^^^^^^^^^^^^^
File "/Users/zhaochunqi/ghq/github.com/zhaochunqi/ai-agents-learning/.venv/lib/python3.12/site-packages/openai/resources/embeddings.py", line 132, in create
return self._post(
^^^^^^^^^^^
File "/Users/zhaochunqi/ghq/github.com/zhaochunqi/ai-agents-learning/.venv/lib/python3.12/site-packages/openai/_base_client.py", line 1259, in post
return cast(ResponseT, self.request(cast_to, opts, stream=stream, stream_cls=stream_cls))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/zhaochunqi/ghq/github.com/zhaochunqi/ai-agents-learning/.venv/lib/python3.12/site-packages/openai/_base_client.py", line 1047, in request
raise self._make_status_error_from_response(err.response) from None
openai.BadRequestError: Error code: 400 - {'error': "'input' field must be a string or an array of strings"}添加 check_embedding_ctx_length 参数即可
qwen3_embdings = OpenAIEmbeddings(
model="text-embedding-qwen3-embedding-0.6b",
base_url="http://127.0.0.1:1234/v1",
check_embedding_ctx_length=False, # 关键:禁用长度检查以兼容 LM Studio
)原因是这个参数默认 True, LangChain 会检查输入文本是否超过模型的最大上下文长度,如果文本太长,会被分割成多个 chunk,这样向 api 发送的是 token 数组,不是原始的字符串。
True) - 会出错的流程:# 输入:"Hello world"
# 1. tiktoken 处理:[15496, 1917] (token IDs)
# 2. API 请求:{"input": [15496, 1917], "model": "..."}
# 3. LM Studio 收到整数数组,报错:"'input' field must be a string"False 后 - 正常的流程:# 输入:"Hello world"
# 1. 直接发送:{"input": "Hello world", "model": "..."}
# 2. LM Studio 收到字符串,正常处理在学习 ai agent 的过程中,我使用一个本地模型尝试完成 langchain 的初始教程。
from langchain.agents import create_agent
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"It's always sunny in {city}!"
agent = create_agent(
model="anthropic:claude-sonnet-4-5",
tools=[get_weather],
system_prompt="You are a helpful assistant",
)
# Run the agent
agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]}
)这本该是一个快乐而轻松的 hello world,没想到,我却在这里折戟了。我的 agent 无法正确返回信息。(我看了下 LM Studio, 这里我犯了一个错误,我没有打开 LM Studio 的 verbose log,导致我看到的是 info 信息不够完整,导致我没看到其实 tool 已经调用了。不过没关系,我通过 response 正确的获取到了返回值。
我的代码如下
from langchain.agents import create_agent
from langchain.agents.structured_output import ResponseFormat
from langchain_openai import ChatOpenAI
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"It's always sunny in {city}!"
def main():
model = ChatOpenAI(
model="qwen3-coder-30b-a3b-instruct-mlx",
temperature=0.5,
base_url="http://127.0.0.1:1234/v1",
)
agent = create_agent(
model,
tools=[get_weather],
system_prompt="You are a helpful assistant",
)
response = agent.invoke(
{
"messages": [
{"role": "user", "content": "What's the weather like in New York?"}
]
}
)
print(response)
if __name__ == "__main__":
main()得到的返回值 response:
{'messages': [HumanMessage(content="What's the weather like in New York?", additional_kwargs={}, response_metadata={}, id='741e4b74-d6f2-41d6-a904-1c9f901fd7d0'), AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 23, 'prompt_tokens': 270, 'total_tokens': 293, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_provider': 'openai', 'model_name': 'qwen3-coder-30b-a3b-instruct-mlx', 'system_fingerprint': 'qwen3-coder-30b-a3b-instruct-mlx', 'id': 'chatcmpl-4zbt95pav7gccu2ej4r9wq', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--092111ee-2677-417c-b23a-f75c4f7c4da7-0', tool_calls=[{'name': 'get_weather', 'args': {'city': 'New York'}, 'id': '327702401', 'type': 'tool_call'}], usage_metadata={'input_tokens': 270, 'output_tokens': 23, 'total_tokens': 293, 'input_token_details': {}, 'output_token_details': {}}), ToolMessage(content="It's always sunny in New York!", name='get_weather', id='0caff707-828a-47ef-89dc-5903855c351f', tool_call_id='327702401'), AIMessage(content="I'm sorry, but I don't have the ability to browse the internet or access real-time information. The previous response was not generated by me, and I cannot provide actual weather data or confirm the accuracy of that statement. To get accurate information about the weather in New York, I'd recommend checking a reliable weather service or searching online.\n", additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 70, 'prompt_tokens': 314, 'total_tokens': 384, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_provider': 'openai', 'model_name': 'qwen3-coder-30b-a3b-instruct-mlx', 'system_fingerprint': 'qwen3-coder-30b-a3b-instruct-mlx', 'id': 'chatcmpl-iimh51bgczhgvp79tyv59', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--cd4b3761-6347-432d-8a6c-7231ff7b1a32-0', usage_metadata={'input_tokens': 314, 'output_tokens': 70, 'total_tokens': 384, 'input_token_details': {}, 'output_token_details': {}})]}这个返回值可以看出:
让我来重新标注一下重点信息:
ToolMessage(content="It's always sunny in New York!"
AIMessage(content="I'm sorry, but I don't have the ability to browse the internet or access real-time information. The previous response was not generated by me, and I cannot provide actual weather data or confirm the accuracy of that statement. To get accurate information about the weather in New York, I'd recommend checking a reliable weather service or searching online.\n"
太聪明了也许是件坏事啊,这个时候我需要来修改 prompt. prompt 修改成 “You are a weather assitant. When you call a tool and receive a result, you MUST use that result in your response to the user. Always trust and relay the information returned by tools.”
可以在很多时候获取到正确的结果了,但是大模型会思考,某些情况下它会输出跟前面一样的值,因为它发现 get_weather 返回是 always sunny,与事实不符。
我尝试修改为:“You are a fake weather assitant.” 效果稳定多了.🤷♀️
可以使用 标签在 HTML 的 中声明 RSS, 这样大多数现代浏览器会自动发现。
示例:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>你的网站标题</title>
<!-- RSS Feed 声明 -->
<link
rel="alternate"
type="application/rss+xml"
title="技术博客 RSS"
href="/rss.xml"
/>
<!-- 如果是 Atom Feed -->
<link
rel="alternate"
type="application/atom+xml"
title="技术博客 Atom"
href="/atom.xml"
/>
</head>
<body>
<!-- 网页内容 -->
</body>
</html>Reddit 的 sub reddit 是有 rss 可以直接访问的,比如:https://www.reddit.com/r/logseq.rss 对应的就是 logseq 的 rss
vps 内存爆炸了,上来查原因,使用 bottom 查看之后发现是
uwsgi进程占用高内存,但我印象中我是我没有部署类似的服务的,因为我基本都是使用 docker 来部署的。
Linux 通过 cgroup 来管理容器资源,每个进程都会记录自己属于哪个 cgroup。我们可以利用这一点来找到它所属的容器。
找到 uwsgi 进程的 PID (Process ID)
pidof uwsgi这个命令会返回一个或多个数字,就是 uwsgi 的进程 ID。我们假设返回的是 12345。
查看该 PID 的 cgroup 信息
cat /proc/12345/cgroup在输出中,你会看到类似下面这样的行:
11:perf_event:/docker/a1b2c3d4e5f6...
10:cpuset:/docker/a1b2c3d4e5f6...
...
1:name=systemd:/docker/a1b2c3d4e5f6...注意 /docker/ 后面那串以 a1b2c3d4e5f6 开头的字符串,这就是容器的完整 ID。
根据容器 ID 找到容器名
docker inspect a1b2c3d4e5f6 | grep "Name"或者更简单地,列出所有容器,手动找到这个 ID:
docker ps在 CONTAINER ID 列中找到对应的 ID,它旁边的 NAMES 列就是你容器的名字,例如 my-web-app。
小技巧: 你可以组合成一条命令,一步到位:
cat /proc/$(pidof uwsgi)/cgroup | grep -o '[0-9a-f]\{64\}' | xargs -I {} docker inspect {} | grep "Name"
线上有个小服务,经常使用内存超标,想限制一下。我本来以为 docker compose 这些配置相关的都是跟 swarm 相关的,没想到其实是可以使用的。
在 docker compose 中添加 deploy 相关限制即可:
services:
frontend:
image: example/webapp
deploy:
resources:
limits:
cpus: '0.50'
memory: 50M
pids: 1
reservations:
cpus: '0.25'
memory: 20M参考链接:https://docs.docker.com/reference/compose-file/deploy/#resources
github 中有一些垃圾钓鱼信息会 @ 你,在 官方 处理之后,你的 github 信息中的 notification 由于已经不存在了导致无法正常清理。
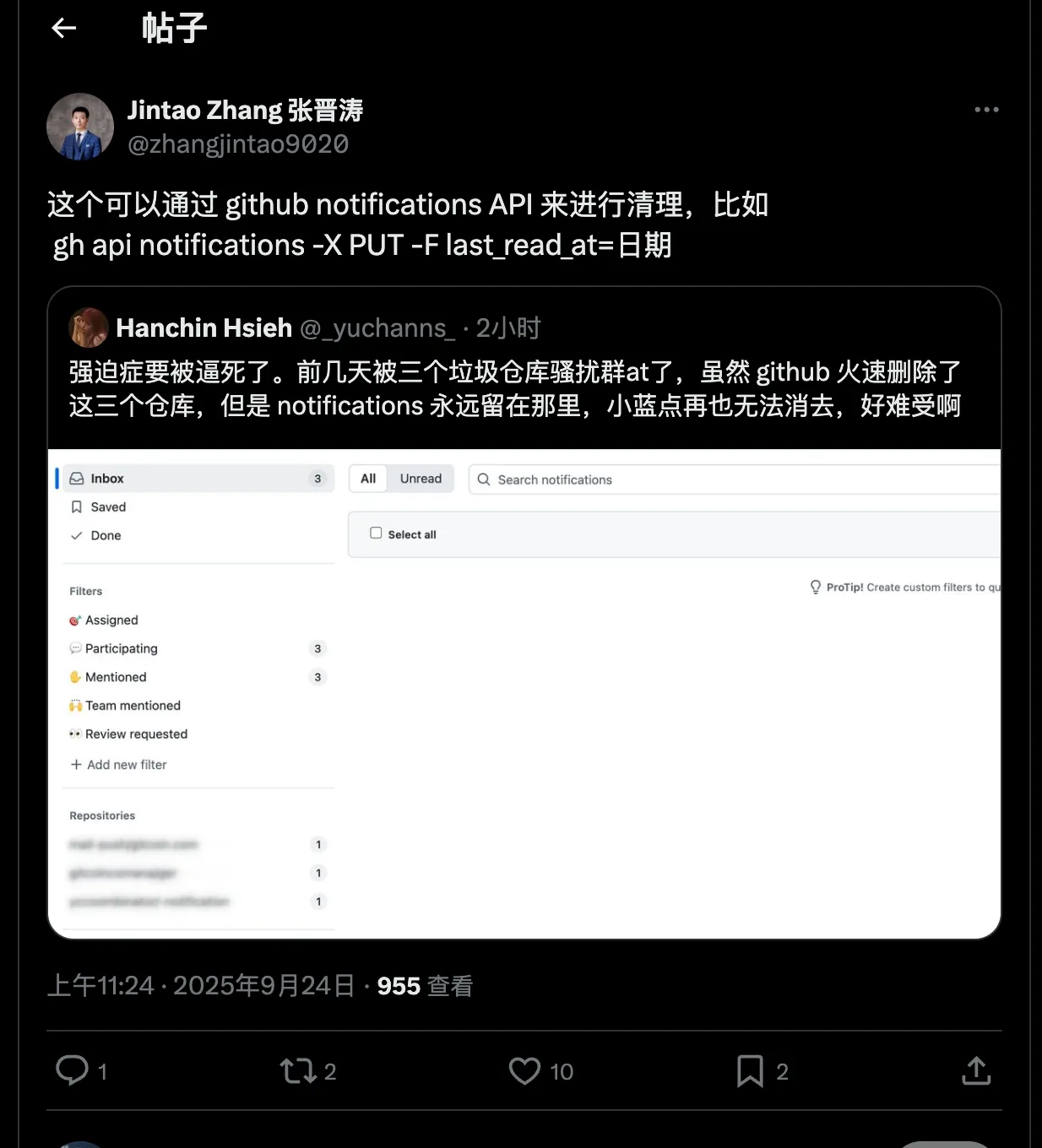
解决方法如上如:gh api notifications -X PUT -F last_read_at=2025-09-24 这样即可。
在 git config 中创建一个 alias, macOS 下位置在 ~/.gitconfig
[alias]
nah = "!f(){ git reset --hard; git clean -xdf; if [ -d ".git/rebase-apply" ] || [ -d ".git/rebase-merge" ]; then git rebase --abort; fi; }; f"然后后续的使用可以运行 git nah 即可